Introduction to Categorical Probability
Posted by Tom Leinster
.")
Guest post by Utku Boduroğlu, Drew McNeely, and Nico Wittrock
When is it appropriate to completely reinvent the wheel? To an outsider, that seems to happen a lot in category theory, and probability theory isn’t spared from this treatment. We’ve had a useful language to describe probability since the 17th century, and it works. Why change it up now?
This may be a tempting question when reading about categorical probability, but we might argue that this isn’t completely reinventing traditional probability from the ground up. Instead, we’re developing a set of tools that allows us to work with traditional probability in a really powerful and intuitive way, and these same tools also allow us define new kinds of uncertainty where traditional probability is limited. In this blog post, we’ll work with examples of both traditional finite probability and nondeterminism, or possibility to show how they can be unified in a single categorical language.
Probability distributions. We want to proceed with our discussion through an example, and so before we introduce everything, consider the following:
You’ve just installed a sprinkler system to your lawn! It is a very advanced piece of technology, measuring a myriad of different things to determine when to turn on the sprinklers… and you have no idea how it does this. In your effort to have an idea of when the system turns on (you pay the water bill, after all) you decided to keep track of how the weather feels and whether your sprinkler is on or not.
You make the following distinctions:
Weather = {sunny, cloudy, rainy},
Humidity = {dry, humid},
Temperature = {hot, mild, cold},
Sprinkler = {on, off}
And you have joint data across these sets for each day:
You make an assumption that the frequency with which each weather event occurred would be an accurate estimate for how it will be in the future, and so you assemble the previous 3 months’ weather data into probability distributions.
We will be relating our definitions and examples to this theme of a lawn sprinkler system. To contextualize our examples, we provide some definitions.
A probability distribution on a finite set is a function assigning to each subset a number such that
- ,
- ,
- and for disjoint subsets , .
For our purposes, a simpler characterization exists from the fact that we can consider a finite set to disjointly consist of its individual points; namely we can think of a probability distribution on to be a function such that
We will also make use of the ket notation to denote a distribution/state on ; for with the values , the following notation also describes a distribution on :
Given this notion, we can model the transition between “state spaces” to by means of a stochastic matrix, which is a matrix such that each column sums to 1, which we denote
Following our established ket notation, we can equivalently describe the action of the channel by
with and forming a probability distribution on .
Furthermore, given two channels and , we also have a way of obtaining a composite channel , by the Chapman-Kolmogorov equation, defining the channel
We interpret distributions to be channels from the singleton set to their respective sets, e.g.: , , . Then, composing any such distribution with a channel will again yield a distribution
Consider the example scenario we described above. Suppose that you compiled the historical weather data into the following probability distribution (more to come about in just a second):
From the table in the example, we can obtain the following channel (if we assume the principle of indifference, i.e., that the entries in the table all occur with equal probability–which is the case, as we have a list of observations)
where is if the combination occurs in the table above, and otherwise; analogously for .
Then, by everything we’ve established so far, we can reason about the likelihood that the sprinkler will turn on the next day by composing the state of the climate with the channel to obtain a state of the sprinkler, computed
All in all, along with the identity matrices, all this data assembles into the category with
- objects: finite sets
- morphisms: stochastic matrices
- where the composition is determined through the Chapman-Kolmogorov equation
This is one of the first examples of a Markov category that we will be looking at, and it will be a good baseline to observe why a Markov category is defined the way it is.
Possibility distributions. Markov categories need not only house probabilistic models of uncertainty; we’ll see that the following also forms a Markov category:
Consider a channel between two finite sets , to be an assignment such that each is a non-empty subset. Defining the composition to be
and the identities as gives us the Markov category of possibilities!
The same data from the example can be used in a possibilistic way as well; a channel can map the sprinkler to all the possible states of weather/climate where the sprinkler has turned on etc. Then, a state is just a set of possible configurations, and the composed state is the set of all possible configurations one can reach from the initial configurations of .
Something you may have noticed from the two examples of morphisms of Markov categories is that fixing an element yields some structure attached to with “desirable properties”: in the case of , we have that each is a probability distribution on – in fact, the Chapman-Kolmogorov formula further provides a way to obtain a probability distribution from a probability distribution of probability distributions. In the case of , each is a non-empty subset of , and the composition is provided through the union of a set of sets.
This is not a coincidence: we will see that for certain monads, the Kleisli category they yield turn out to be Markov categories! The monads in question will provide us descriptions of what the channels are, as well as the rule for composition.
Kleisli Categories. If you are familiar with Kleisli categories, you might have uncovered from above as the Kleisli category of the normalized finite powerset monad. In fact, it turns out that many Markov categories of interest arise as Kleisli categories of so-called probability monads, such as the Giry monad, Radon monad, or distribution monads over semirings. Rather than explaining (technical) details of these, we want to dive into the underlying construction.
If you do not know Kleisli categories–don’t worry, we’ll try to explain it on the go, focusing on the relevant properties for our purpose. The idea is the following:
- Take a cartesian monoidal category , representing deterministic processes and
- Introduce non-deterministic processes as a monadic effect by a probability monad . The Kleisli category of has the same objects as , and morphisms We call these Kleisli maps.
Example. as already mentioned, the category (modelling possible transitions between finite sets) is the Kleisli category of the normalized finite powerset monad which assigns to a set “Normalization” here means that we exclude the empty set.
While the previous example captures possibility, the following is the most general framework for probability:
Example. The Markov cateory is the Kleisli category of the Giry monad on the (cartesian monoida) category of measurable spaces, sending a measurable space to the space of distributions on it (a.k.a probability measures). Its Kleisli morphisms are known as Markov kernels. (Hence the name Markov categories!) By definition, these are measurable functions , meaning that each point is assigned a distribution on : normal distributions, uniform distribution, delta distribution (a.k.a Dirac measure), … Regard it as a stochastic process with input and probabilistic output . If the weather is sunny tomorrow, will the sprinkler switch on? Well, probably… In contrast, morphisms in (i.e. measurable functions) are deterministic, as their output are points being definitely determined by their input .
A general definition of determinism in Markov categories follows below. Before, let’s investigate the term process, by which we mean morphisms in a monoidal category: the usual composition amounts to the concatenation of processes, while the tensor product merges two subsystems into one, by running them “in parallel”.
For our category of “deterministic processes”, this is straight forward; being cartesian monoidal means
- it has a terminal object .
it has products and projection pairs satisfying the universal property of the product:

it has a symmetric monoidal structure induced by 1. and 2.
Things are more complicated for the Kleisli category : to get a tensor product, we need the monad to be commutative, i.e., it comes with well behaved zipper functions (in ) To be precise, we require to make a symmetric monoidal functor, such that multiplication and unit of the monad are monoidal natural transformations.
Kleisli maps and may then be tensored as
Example. For the power set-monad , the zipper maps two subsets and to . Kleisli maps and hence have the tensor product
Example. The zipper for the Giry monad assigns the product measure to probability measures , . Tensoring two Markov kernels and yields
In categorical terms, the induced symmetric monoidal structure on the Kleisli category is such that the Kleisli functor is strict symmetric monoidal.
But we want more: we want the Kleisli functor to preserve the projection pairs , in that the following diagrams (in !) commute for :

There are multiple equivalent requirements:
- and are natural transformations;
- preserves the terminal object (in );
- is a terminal object in , which is thus semicartesian.
Example. The power set monad preserves the terminal object if it is “normalized” in the above sense: .
As a consequence, has weak products: any pair of Kleisli maps , factorizes as:

with the copy process of (The lower triangles commute, as is a functor and .)
However, the vertical Kleisli map in that diagram is not unique–hence the term semicartesian–as the following example shows.
In the Kleisli category of the Giry-monad, consider the uniform distributions on and , i.e. Markov kernels Then the product-diagram commutes for both of the following Markov kernels : Which one is obtained as above via ?
In probability theory, this ambiguity is known as the fact that Markov kernels are not determined by their marginalizations and . From a more category theoretic perspective, it means that the family of copy morphisms is not natural.
At first glance, this may not seem very convenient: considering something non-natural–but we want this, in order to capture uncertainty. We will give the details below (in subsection “Determinism”) and return to the big picture from above: a probability monad on a cartesian monoidal category induces probabilistic/non-deterministic morphisms, which destroy the uniqueness constraint of the product and leaves us with weak products in .
In the corresponding diagram of weak products, we have already seen the rectangles on top commute if and only if is semicartesian.
Have you noticed that the triangles at the bottom look like a counitality constraint? In fact, each is a commutative comonoid object in . This is the starting point for the general definition of Markov categories.
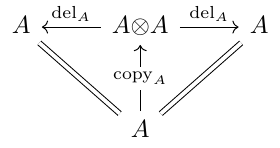
Markov Categories. Let’s start with a terse definition: A Markov category is a semi-Cartesian category where every object is a commutative comonoid compatible with the monoidal structure.
In more detail, a Markov category is a symmetric monoidal category where each object is equipped with
a deletion map depicted as

Even though they differ from the deletion maps from the section on Kleisli categories, they are morally the same.
a copy map depicted as
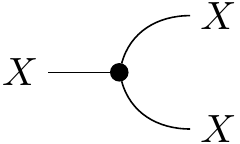
such that
the collection of deletion maps is natural:

Equivalently, is required to be terminal. Hence, the deletion maps are compatible with the tensor product:

the collection of copy maps is compatible with the symmetric monoidal structure

each is a commutative comonoid:

Let’s go a little bit more in-depth into why each of these axioms are required:
It is obvious why composition and identity is important to form a category. We note, however, that we want to think of constituents of a Markov category as states and channels that take states to states. So, in such a case, compositionality is important to be able to talk about “taking states to states”, where for a state , we wish for its “pushforward” to be a state as well. We also want to compose (probabilistic) systems out of smaller building blocks. From a more probability theoretic point of view, our theory should allow us to describe distributions over joint variables.
There are also reasons why we want the comultiplication structure. We can think of the copy map as a Markov kernel that takes an input and outputs a Dirac delta distribution on its diagonal, . In our example, the copy morphism on our set of weather conditions forms the following stochastic matrix:
When a distribution is postcomposed with a copy, it will land on the diagonal in the joint space. So for instance, if a distribution on weather states is , then we get
Cartesian categories come equipped with diagonal maps that do something very similar to this. Paired with the projections, this makes all objects of Cartesian categories comonoids as well, and in fact all Cartesian categories are Markov categories. These don’t make for very interesting categories in terms of probability though, since all morphisms are deterministic as mentioned earlier. But if we have a probability monad on a Cartesian category, we can transport the diagonal maps into its Kleisli category, and these become precisely the copy maps. So why do we want this comultiplication structure on our objects? If we think of string diagrams as having pipes through which information flows, then it’s useful to duplicate information and run different transformations on their parallel streams for comparison.
In probability theory, we have a kind of projection known as marginalization. Here, we build this projection morphism using the delete map and densoring it with an identity. Naturality of the deletion maps corresponds to normalization of Markov kernels. More generally speaking, deleting information seems desirable in a framework for information processing (even though it’s impossible in quantum information theory). Naturality of , i.e. terminality of , means that deleting an output of a process deletes the whole process.
As seen above (section on Kleisli categories), this allows for weak products; this is the category theoretic description of uncertainty, in contrast to determinism of cartesian monoidal categories.
Common Markov categories. There are tons of Markov categories out there, some quite obscure, but also many whose compositional computations are used every single day. As we’ve seen, every Cartesian category such as is Markov, albeit one that doesn’t contain uncertainty. But as we’ve also seen, for each affine commutative monad, whose functor can represent the collection of uncertainty distributions over an object, its Kleisli category is Markov. The classic example here is for the Giry monad. The primary topic for our research week during the Adjoint School was actually to try to find a monad for imprecise probability distributions such as Dempster-Shafer belief functions. Our method so far is to try to find a type of Riesz representation theorem to equivocate these belief functions with functionals. Since functionals form the continuation monad, then this would be an easy way to prove that our belief functions form a monad themselves.
There are other Markov categories that aren’t quite Kleisli categories, but they come from very similar constructions such as relative monads or decorated linear maps. In our example we’ve been working with , which has finite sets and stochastic matrices, and another common one is , which contains Gaussian normal distributions on and affine maps with Gaussian noise.
Additional Axioms and Properties Markov categories as we’ve built them so far form a great setting for probability, but the characters on stage have a lot more depth to them than just being stochastic kernels. Many morphisms have relationships with each other that correspond to useful notions in traditional probability.
Determinism. Looking back at Cartesian categories, there seems to be something special about them: all of their morphisms seem to be “deterministic,” in that they map a single input to a single output. This isn’t a very categorical notion though, so let’s try to find properties of Cartesian categories that encapsulate the idea that there’s no uncertainty in the morphism outputs.
One unique property that Cartesian categories have over Markov categories is that their diagonal maps are natural in a certain sense. Explicitly, if we equate the two inputs of the tensor product to form a “squaring” endofunctor , then the collection of diagonal maps in a Cartesian category form a natural transformation . The copy maps in a general Markov category do not follow the naturality square for all morphisms, which translates to the following string diagram:
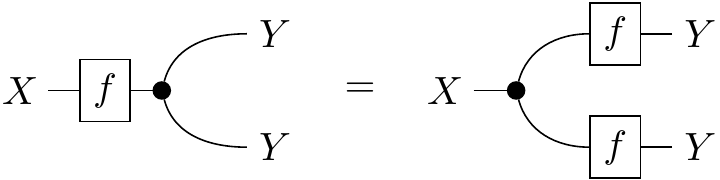
This actually makes sense as a condition for a kernel to be deterministic! If we really think about what uncertainty means, it boils down to the idea that many different outputs of a process could be possible given a single input. Say the process maps pressure to weather state, and it’s a low pressure day. You could duplicate these exact pressure conditions on the other side of town, but the weather gods might decide to bless your neighbors with rain while they leave you only with cloud cover. This would be different from copying your weather state and pasting it over your friend’s house. On the other hand, a deterministic process could be from weather to sprinkler, if it’s always guaranteed to sprinkle when the sun is out. If you and your friend have identical weather, there’s no difference between each sprinkler having its own sun sensor or a single sensor controlling both.
Here’s a concrete example with possibilistic states: Say the forecast today has as possibilities. If we copy this, we get which is not equal to . On the other hand, we could look outside and determine the weather is certainly . Then copying and tensoring would both give us .
Only Cartesian categories have all-deterministic morphisms, and so we also call them deterministic Markov categories. Further, all of the following are equivalent statemtents:
- A Markov category is deterministic
- Its copy map is natural
- It is Cartesian
General Markov categories have not only deterministic morphisms, but they at least have a few. In fact, it’s not hard to prove that copies, deletes, swaps, and identities are all deterministic themselves, and that determinism is closed under composition. This means that the collection of deterministic morphisms form a wide subcategory of , which we call , and that category is Markov itself!
Example. The deterministic subcategory of is (equivalent to) .
Example. Similarly, has as deterministic subcategory. However, this does not translate to the infinite case: !
Conditionals. In traditional probability, we define a conditional probability as “the probability of one event given that another event is already known to have occurred.” In traditional probability, we define a conditional probability as “the probability of one event given that another event is already known to have occurred.” This is constructed from a joint probability distribution, whose values are “renormalized” to the restriction of the known event.
For example, say the forecast for today given jointly for temperature and weather, and the data is given in the table below:
Now if we feel that it’s cold outside, what’s our new estimate for the chance of rain? We can calculate this by restricting our data to only the event of low pressure, and renormalizing that data to sum up again to 1. Renormalization is easily done by dividing our values by the total probability of that restriction, which is . So the chance of rain given that it’s cold is .
From here, we have a general formula for calculating conditional probability in the finite case:
where the traditional notation for the conditional probability of given is given by a pipe separating them. If this looks exactly like the notation for stochastic kernels, this is no coincidence! In fact, we can calculate these quantities for all outcomes to generate a stochastic kernel from to :
We give this kernel the same name as but with the subscript to show that we turned ’s output into an input.
There are many different formulas for conditionals with respect to different kinds of probability, but how do we generalize this concept to cover all types of uncertainty, and put it in the language of our framework? The key insight is to recognize that at the end, we were able to build a morphism from to that used the relationships between the two variables in . In fact the information contained in gives it a special property which allows it to serve as sort of a “recovery process” for some data in , as shown in the diagram below.
Imagine you’ve forgotten the weather portion of today’s forecast, but you remember the predictions on what today’s temperature will be. This is represented by the marginalization . If you’ve calculated this conditional kernel earlier and stored it as backup, then you can simply graph this out with your remaining data to fully restore the original information! We’ll use this as the basis for our definition, but we’ll add parametrization with an input:
Definition. Given a morphism , a conditional on which we call is any morphism, which satisfies
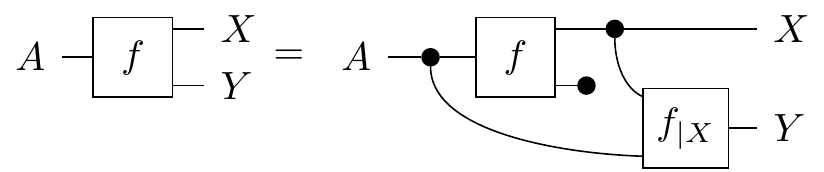
which again can act as a recovery process from to (parametrized by ) if the original data on has been deleted.
Unfortunately conditional morphisms are difficult to find, are not unique, and might not even exist for a given kernel. However if they do exist, then they are unique up to a certain equivalence called almost sure equality. And there are many Markov categories which do have conditionals for every morphism (such as , unlike ), and there are even several Markov categories for which we have closed-form solutions for conditionals.
To make string diagrams simpler, we often draw conditionals like so:
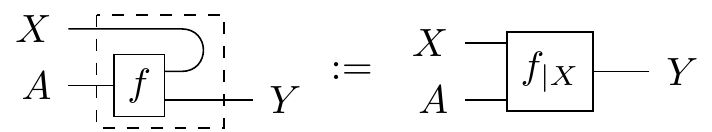
where we “bend the wire back” to signify which output has been turned into an input. We should note though, this is only graphical sugar and does not represent some kind of “cap” morphism. In fact, nontrivial compact closed Markov categories do not exist. Conditionals also cannot be built up from compositions of other morphisms, so we put a dashed box around it to signify that the contents inside are “sealed off” from associating with other morphisms on the outside. So when we draw a bunch of morphisms inside the dashed box, it means we’re taking the conditional of the morphism resulting from composition of the smaller morphisms. Even though the dash box seals the insides, luckily there are some properties of conditionals that allow us to do rewrites. Bent wire notation makes these really nice:
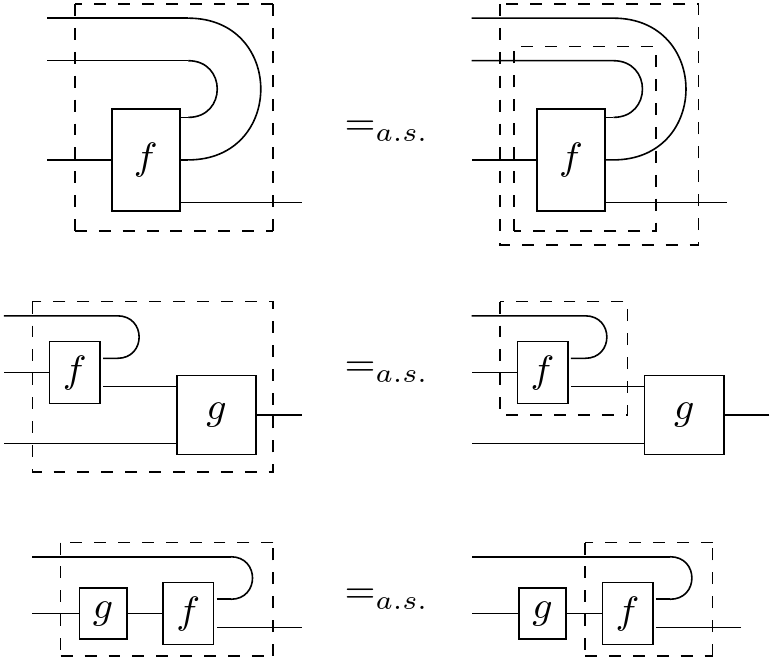
where the in the bottom equation needs to be deterministic.
Conditional Independence. In traditional probability, a joint distribution is said to be independent in its variables if it satisfies for all and .
So for instance, the following joint state on temperature and pressure is independent
The marginals are shown with the labels, so you can see that each entry is the product of its marginals.
However, if we move just one speck of mass over from (High, Hot) to (Low, Hot), then it breaks independence:
This traditional definition seems a little arbitrary, so what does this mean intuitively? String diagrams can help here, and further they will allow us to generalize to any Markov category. First, a very informal definition: we say that a morphism displays independence in its outputs if its conditional doesn’t use its bent-wire input at all. We also say that its outputs are not correlated with each other, or they don’t share mutual information.
Let’s look at this more closely in string diagrams with a formal definition:
Definition. A morphism displays , read as “ is independent of given ”, if its conditional can be calculated as
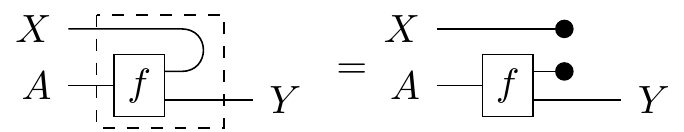
This looks like the bent wire has just been snipped! But if we look back to the definition of conditionals, this encapsulates the idea that there’s no information about contained in . If the conditional is a “data recovery” morphism that reconstructs from the information it shares with , then we notice two things: one, the original has to be used in the conditional, which means the recovery morphism needs to store the entirety of ’s original information to recover it. And two, the input wire juts gets deleted, so it doesn’t use any information from our unforgotten channels during recovery. This means that whatever you know about isn’t useful in reconstructing the information on .
If we do some string diagram manipulation, then we’ll see that this reduces to the traditional definition of independence:
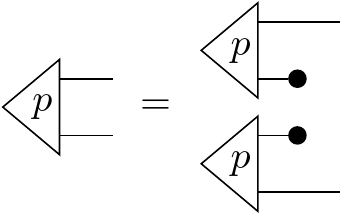
From here, we can see that this definition is actually symmetric: if is independent from , then is also independent from and we can just say that and are independent of each other. Is it possible for and to be only partially independent? What if we can factor out a component of the states that exhibits dependence, and the other components are independent? We can capture that scenario with the following: We say that a morphism with signature , exhibits , read as “ is independent of given input and output ”, if its conditional with respect to and is equal to the conditional with its wire snipped, like so:
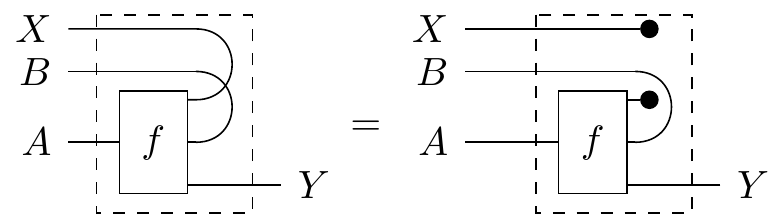
This version of independence has several equivalent definitions, and it is also symmetric.
Conclusion. So what can we do with all these constructions? It’s neat that we now have a graphical language to describe probability, and also we have a unifying language that describes all different types of uncertainty. We’ve already done a lot of work in formulating traditional results in terms of Markov categories, which then generalizes these results to several different types of uncertainty representations. For instance, there are generalized results for the De Finetti Theorem, general constructions for Hidden Markov Models, and graphical ways to do causal inferencing. One benefit to categorifying these constructions could be to simplify the constructions of complicated statistical algorithms by making their code modular: the general categorical construction can be coded in the abstract, and kept separate from code used to build a Markov category.
One other cool thing is that, since the categorical construction is so broad, it allows you to really dive deep into discovering the “meaning” of uncertainty, and how it’s structured. For example, information flow axioms help explain what makes stochastic probability (that is, probabilities valued between 0 and 1) so special as a representation of uncertainty, as opposed to assigning other kinds of values to events.
Currently, there’s an ever-growing list of classical probabilistic notions that are being captured in this categorical language. While it seems like we’re reinventing the wheel with a new language, really what we’re trying to do is just make the wheel bigger.
Re: Introduction to Categorical Probability
This has got to be the best mathematics blog on the Internet. Thank you for taking the time to produce such high-quality content.