An Operational Semantics of Simply-Typed Lambda Calculus With String Diagrams
Posted by Emily Riehl
.")
guest post by Leonardo Luis Torres Villegas and Guillaume Sabbagh
Introduction
String diagrams are ubiquitous in applied category theory. They originate as a graphical notation for representing terms in monoidal categories and since their origins, they have been used not just as a tool for researchers to make reasoning easier but also to formalize and give algebraic semantics to previous graphical formalisms.
On the other hand, it is well known the relationship between simply typed lambda calculus and Cartesian Closed Categories(CCC) throughout Curry-Howard-Lambeck isomorphism. By adding the necessary notation for the extra structure of CCC, we could also represent terms of Cartesian Closed Categories using string diagrams. By mixing these two ideas, it is not crazy to think that if we represent terms of CCC with string diagrams, we should be able to represent computation using string diagrams. This is the goal of this blog, we will use string diagrams to represent simply-typed lambda calculus terms, and computation will be modeled by the idea of a sequence of rewriting steps of string diagrams (i.e. an operational semantics!).
Outline of this blog
Throughout this blog post, we will present many of the ideas in the paper “String Diagrams for lambda calculi and Functional Computation” by Dan R. Ghica and Fabio Zanasi from 2023. In the first section, we will recall the untyped lambda and simply typed lambda calculus. In the next section, we will review the basic concepts and notation of string diagrams for monoidal categories. Then, we will extend our graphical language with the necessary notation to represent terms in a Cartesian Closed Category. Finally, in the last section, we will present the operational semantics for lambda calculus based on string diagrams and study a case example of arithmetics operations and recursion.
Lambda calculus quick quick crash course
We will start by reviewing one of the first and more “simple” models of computation: The lambda calculus. The lambda calculus was originally developed by Alonzo Church when he was studying problems on the foundations of mathematics. Alan Turing proposed almost simultaneously its famous model of computation based on an abstract machine that moves along an infinite tape. The lambda calculus is equivalent to Turing’s model. If we would like to have an intuition about the difference between the two models we would say that the lambda calculus is closer to the idea of software while Turing machines are closer to hardware. The lambda calculus has had a huge influence and applications to different areas of Computer science, logic, and mathematics. In particular to functional programming languages, as lambda calculus provides the foundational theoretical framework upon which functional programming languages are built.
Lambda-calculus is based on a rewrite system. Every term in lambda calculus is morally a function, you can apply functions and abstract functions.
More precisely, a lambda term is defined inductively as follows:
- A variable is a lambda term;
- Given two lambda terms and , is a lambda term representing the application of to ;
- Given a variable and a lambda term , is a lambda term representing the function taking an as input and returning where is a bound variable in , this is called an abstraction.
Function application is left-associative by convention.
Three reductions are usually defined on lambda terms, -conversion allows to change bound variables names to avoid naming conflicts, -reduction apply a function to its argument by replacing the bound variable with the argument, and -reduction which identifies two functions if they give the same output for every input.
We will focus on -reduction as we don’t aim for a super formal approach, and -conversion can be avoided in different ways (using De Bruijn index notation, for instance). -reduction is confluent when working up to -conversion, so that is what we are going to assume throughout this blog.
How to represent simple data types in untyped lambda calculus? Since in untyped lambda calculus everything is a function, the idea is to encode simple data types using only functions in a consistent way. For instance, we can define booleans in the following manner: := and := .
The idea is that a boolean is meant to be used in a if-then-else statement, let be the ‘then’ expression and be the ‘else’ expression, the if-then-else statement can be expressed with where is a boolean. Indeed, if then we have which is equal by definition to which reduces to . If , then yields after two -reduction.
Logical connectors ‘and’, ‘or’, ‘implies’, ‘not’, can be implemented using if-then-else statements, for example which reads if is true then return else return .
We can also represent natural numbers by successive application of a function, these are the Church numerals:
- 0 := a function which applies 0 time;
- 1 := a function which applies 1 time;
- 2 := a function which applies 2 times;
- := recursively, the successor of a number applies one more time to than .
We can define usual functions on numbers:
- :=
- + :=
- * := and so on
What we described above is untyped lambda calculus, but it lacks certain properties due to its computability power. For example, it allows paradoxes such as Kleene-Rosser paradox and Curry’s paradox. To have a better rewriting system, Alonzo Church introduced simply typed lambda calculus.
The idea is to give a type to variables to prevent self application of function. To this end, we consider a typing environment and typing rules:
- This means that a typing assumption in the typing environment should be in the typing relation;
This means that terms constant have appropriate base types (e.g. 5 is an integer);
This means that if is of type when is of type , then the abstraction is of the function type ;
- This means that when you apply a function of type to an argument of type it gives a result of type .
When writing terms, we now have to specify the type of the variables we introduce. The examples above now become:
- 0 :=
- 1 :=
- 2 :=
- :=
- + :=
- * :=
Crucially, we can no longer apply a function to itself: let’s suppose has type , then would mean that must be a function taking as an argument, so , but it now means that should take an argument of type so would be of type and so on which is impossible.
Because we can no longer apply a function to itself, simply typed calculus is no longer Turing complete and every program eventually halts. It is therefore less powerful but has nicer properties than untyped calculus. From now on, we will work with simply typed calculus not just because of its rewrite properties but also because of its strong connections with category theory.
Everything we have explained in a very hurried and informal manner in this section, can be fully formalized and treated with mathematical rigor. The objective of this section is to ensure that those not familiar with lambda calculus do not find it an impediment to continue reading. If the reader wishes to delve deeper or see a more formal treatment of what has been explained and defined in this section, they can refer to “Lambda calculus and combinator: an introduction” by Hindley and Seldin for a classical and treatment or to “Introduction to Higher order categorical logic” by Lambek and Scott for a more categorical approach.
String diagrams
String diagrams for monoidal categories
Why use symmetric monoidal categories? Monoidal categories arise all the time in mathematics and are one of the most studied structures in category theory. In the more applied context, a monoidal category is a suitable algebraic structure if we want to express processes with multiple inputs and multiple outputs.
String diagrams are nice representations of terms in a symmetric monoidal category which exploits our visual pattern recognition of a multigraph’s topology to our advantage.
As a quick reminder, a monoidal category is a sextuplet where:
- is a category;
- is a bifunctor called a tensor product;
- an object called the unit;
- is a natural isomorphism called the associator;
- are natural isomorphisms called respectively the left and right unitor;
such that the triangle and the pentagon diagrams commute:
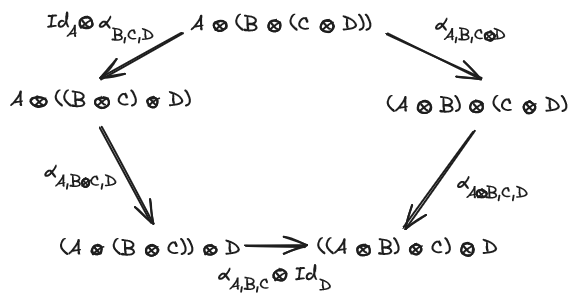
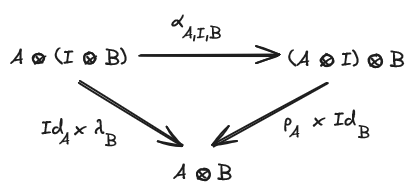
A strict monoidal category is a monoidal category where the associator and the unitors are identities, every monoidal category is equivalent to a strict one so we may use strict monoidal categories from now on.
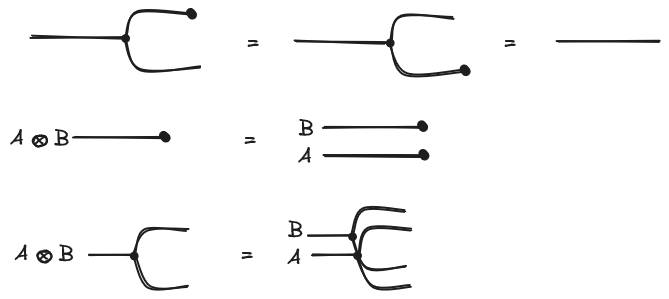
With string diagrams, the objects of the category are represented as labelled wires, the morphisms as named boxes and the composition of two morphisms is the horizontal concatenation of string diagrams and the tensor product of two objects/morphisms the vertical juxtaposition:
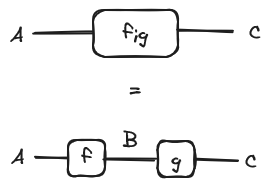
.png)
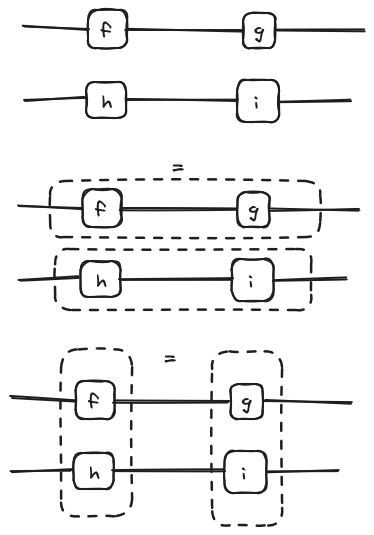
We already see the usefulness of string diagrams when seeing the interchange law. The interchange law states that .
It becomes trivial when seen as a string diagram:
A symmetric monoidal category is a monoidal category equipped with a natural isomorphism called a braiding such that . We will represent the braiding morphisms are as follows:
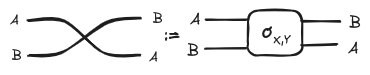
Again the topology of the string diagram’s underlying multigraph reflects the properties of the braiding when the monoidal category is symmetric.
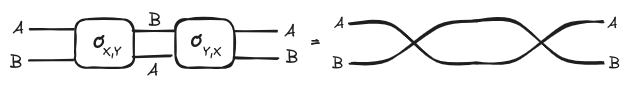
To put it in a nutshell, string diagrams are great visualization tools to represent morphisms in a symmetric monoidal category because they exploit our visual pattern recognition of the topology of a graph: we intuitively understand how wiring boxes work.
Functors boxes
So far, we have reviewed the standard notation for string diagrams on monoidal categories. Now we will introduce how to represent functors in our graphical language.
Let and be two categories. And let be a functor between them. Then the functor F applied to a morphism f is represented as an F-labelled box:
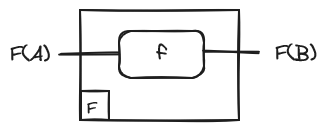
Intuitively, the box acts as a kind of boundary. What it is inside the functor box (wires and boxes) lives in , while the outside lives in .
As an example, the composition law of functors would look like this using the above notation:
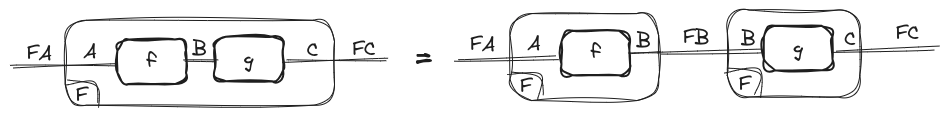
Adjoint and abstraction
One of the categorical constructions we will use the most throughout this blog is adjunctions, so we would like to represent them in our graphical notation. In particular, we will make use of the unit/counit definition. The reason for doing this, is, first because the unit and counit of the particular adjunction pair that we are interested in will play an important role, and second because the unit/counit presentation is arguably the best when using string diagrams.
What should we add to represent adjunctions in our graphical notation? Well… nothing! We already have a notation for functors. Natural transformations, from the point of view of string diagrams, are just collections of morphisms, so the components of a natural transformation are represented as boxes, just like any other morphism in the category. However, since the unit and counit will play a fundamental role, it will be convenient for us to have a special notation for both.
We will represent the unit as a right-pointing half-circle with the object components in the middle. For the counit, it is analogous but points to the left.

Now the equations look like this:
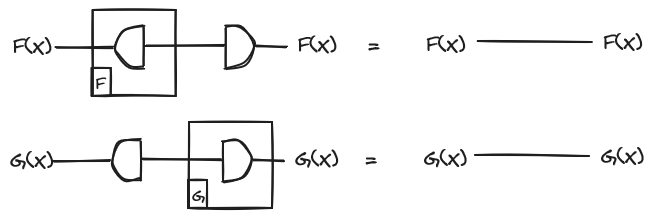
The particular pair of adjoints that we are interested in is the pair consisting of the tensor product functor and its right adjoint which we write as , where is a monoidal category. This adjunction is also usually written as
When the functor has a right adjoint we say that is a closed monoidal category.
The importance of this pair of adjoints lies in their counit and unit, which allow us to represent the idea of application and abstraction, that one we presented in the previous section, respectively.
The first one makes total sense because if we analyze the form of the counit, we will discover that it perfectly matches the function application form:
On the other hand, the counit has the following form:
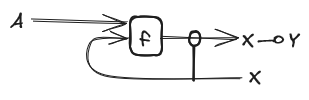
If we mix the counit with the functor we can do abstraction of morphisms and currying (note that abstraction is currying with the unit: ). So for any morphism we will denote its abstraction as
We will use this construction a lot so we will use a syntactic sugar to denote it in our graphical formalism.

Notice that this syntactic sugar is quite suggestive since the hanging wire gives us the idea of a quantified variable waiting to be used, but it is important to note that this is just a graphical convention.
Another usual notation is the clasp of the Rosetta Stone paper by Baez and Stay:
Now Cartesian
We finish this section with the last ingredient necessary to represent graphically the terms of a Cartesian Closed Category, which is the product object. The motivation for having this construction is that, in our simple programming language, we would like to be able to represent functions that take more than one parameter. Similarly, it would be useful to have the ability to duplicate the output of a function or discard it (yes, this is no quantum computing!), which is directly related to the previous point.
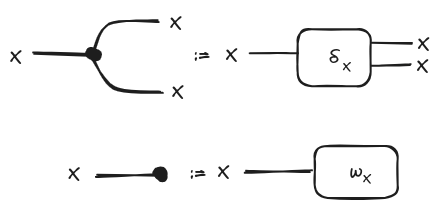
With this in mind, we introduce two natural transformations and , which we call copy and delete, respectively. Before giving the equations necessary to call a category “cartesian”, as we mentioned before, these natural transformations represent the ideas of duplicating and discarding the output of a function.
Since these two constructions will play a fundamental role in our task of representing functional programs, we will give them a special syntax:
And as we ask them to be natural, the naturality condition looks like this:
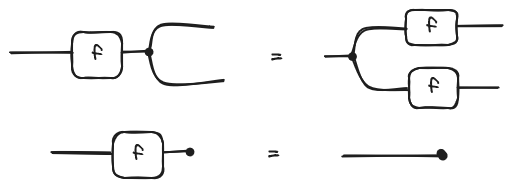
So finally, we will say that a symmetric monoidal tensor is a Cartesian product if, for each object in the category, the above-mentioned monoidal transformations and exist such that:
Note how we are expressing the properties directly using string diagrams! Just in case you’d like to see how these properties look in classical notation, here they are:
A fun exercise for the non-lazy reader: This product definition is not the standard in category theory literature, which tends to use universality. How would you prove the equivalence between the two definitions using string diagrams? (for a solution see definition 3.13, chapter 3 of “String Diagrams for lambda calculi and Functional Computation” by Dan R. Ghica and Fabio Zanasi)
Some examples
Now that we have all the necessary structure, let’s look at some examples of diagrams representing terms in the lambda calculus. Let’s start with the identity applied to itself . We have two abstractions and one application. Its string diagram representation is:
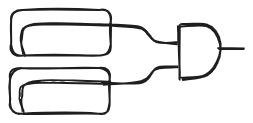
Now let’s draw the function defined earlier which is: . This one consists of only two abstractions:
.png)
And if we would like to apply the previous function:
A comment on the relationship between lambda calculus
Although in the previous examples, we have been using it implicitly, we never provided the explicit relationship between lambda calculus and its respective category. For the sake of completeness and as a technical aside, we briefly comment that to construct the categorical interpretation, we take the types as objects of the category, and the morphisms are given by the tuples where is a variable and is a term with the only possible free variable is x. And the composition is giving by chaining function applications, i.e. we take the output of one function and use it as the input for another (This can be formalized through term substitution). It is not the goal of this blog to provide a formal treatment of this (although it is a very interesting topic for a blog!). Interested readers can refer to the famous text “Introduction to Higher Order Categorical Logic” by Lambek and Scott.
The operational semantics
Now we have all the prerequisites for presenting our main topic. We are going to give an operational semantics based on string diagrams. This will consist of a series of rules that allow us to represent computation as a sequence of applications of such rules. But before doing that we have to decide a little detail, we must establish our evaluation strategy. When computing the application you could first evaluate the argument and then apply to (call-by-value strategy) or you could first substitute in the body of and postpone the evaluation of (call-by-name strategy). For this blog, we will use the call-by-value strategy.
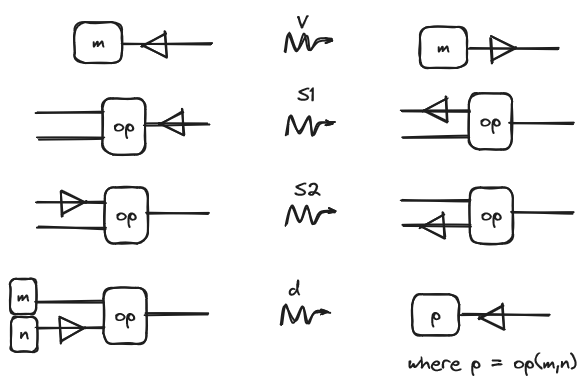
Now we can start to describe our operational semantics. First we will add a decorator to the string diagrams. This decorator is a syntactic construct applied to a specific wire, used for redex search and evaluation scheduling. Our interpretation of the decorator is as follows: when the decorator points left, it indicates the part of the string diagram that is about to be evaluated. When the decorator points right, it signifies that the indicated part has just been evaluated. With this in mind, the rules that will model the behavior of the decorator, and therefore execution, are the following ones:
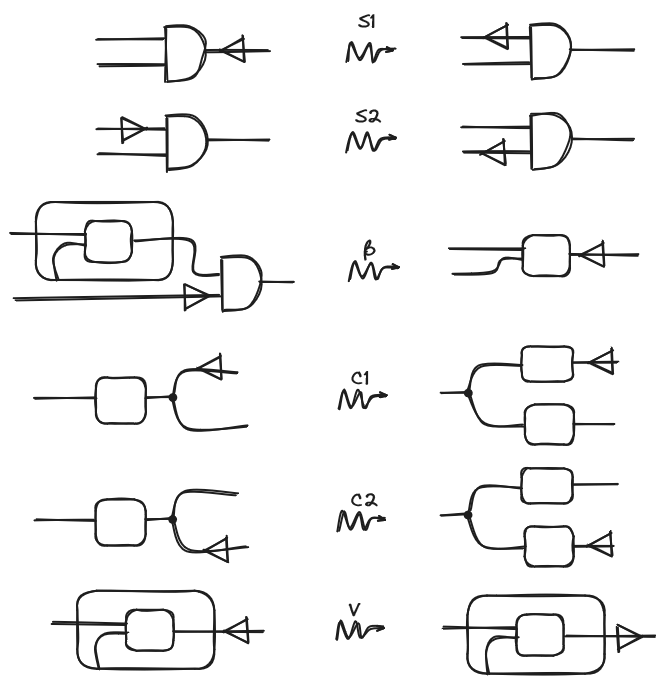
We argue that most of the rules are quite intuitive after some contemplation but let’s explain them a little:
- The first two (S1 and S2) models what we just said before about the evaluation strategy: (S1) For evaluating an application first we evaluate the function and (S2) After evaluating a function, evaluate the argument.
- This rule represents the rule of lambda calculus and says that after evaluating the argument, evaluate the result.
- The next two are about how to treat copying: (C1) When encountering a copying node, copy in both branches of the boxes, and (C2) is analogous but from the other side.
- The last one says that the abstraction is a value, here we won’t get into detail about this but basically, this means that when we encounter a lonely abstraction we stop the evaluation (note the change of direction of the decorator).
A parenthesis about rewriting: The reader might have noticed that we are talking about “rewriting” string diagrams, but at no point do we formally define what this means or how we can do it. This is beyond the scope of this blog, but for the curious reader, we strongly recommend our colleagues’ blog on the mathematical foundation behind string diagram rewriting:
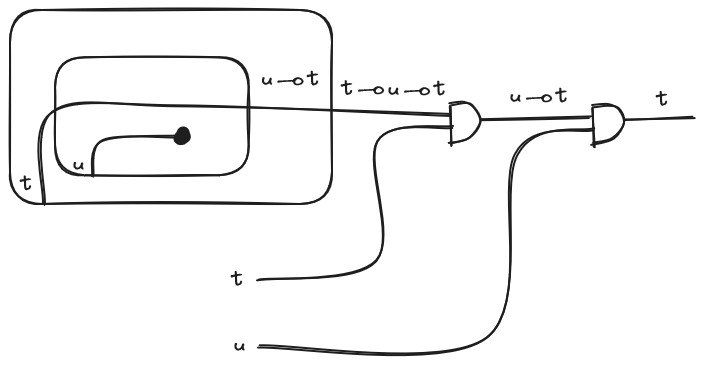
Before we start adding cool stuff to our simply-type lambda calculus let’s see our first basic example. Let’s apply our operational rules to the string diagram of the identity function that we showed in the previous section:
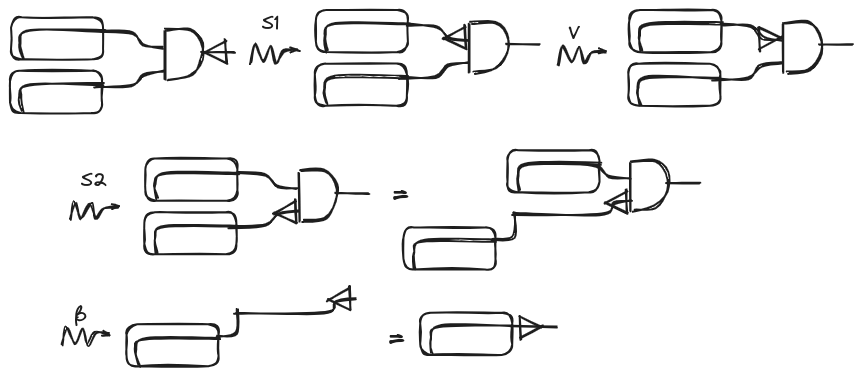
Aritmetic, logic operations, and recursion
Let’s have a little fun and start defining the operations we would like to have in our language. We will provide the definitions of these operations and their operational semantics.
First, for doing arithmetics, we start adding a numerical type , with its respective constants that will have the form . Let’s add a binary arithmetic operator. Now we need to think about what rewrite rules we are going to add. It is not hard to come up with the following rules:
The first three are “reused” as they come from the order of evaluation and the idea that the constants are values and require no further evaluation. And finally, we have a reduction rule that tells us how to apply the operator to two constants. For example, for the operator , there would be a rule for every pair of integers (e.g. , , and so on).
Note that those rules work for any binary operation by simply changing rule !
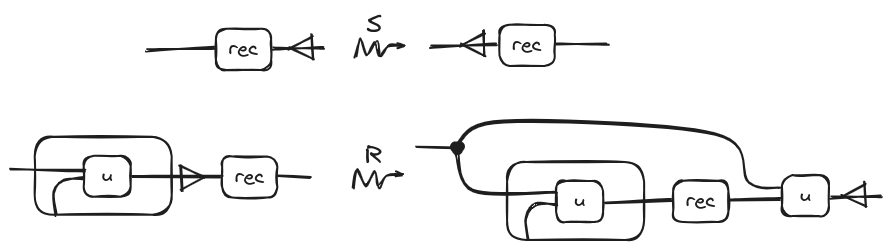
Our last example consists of one of the most common characteristics in all modern programming language: Recursion. As with the previous example first we need to introduce a recursion operation, which we call , with the following rule:
The right side of the rule is just a fancy way of saying “the term that we get replacing f for every occurrence of in u”. Note how this rule doesn’t reduce the original term but expands it!
Then the structural rule that we will add for the above operation is the following one:
Why do these rules work? Well, the first one is obvious; it is just the analog of the structural rules but for unary operations. However, the second rule is trickier than the previous ones we have presented. This rule, whenever it encounters an abstraction already executed with the operation following it, uncurry the function and passes the same diagram as second argument before the rewriting. It is important to note that this rule does not contract the diagram but expands it.
If we start repeatedly applying this rule, we get something like this:
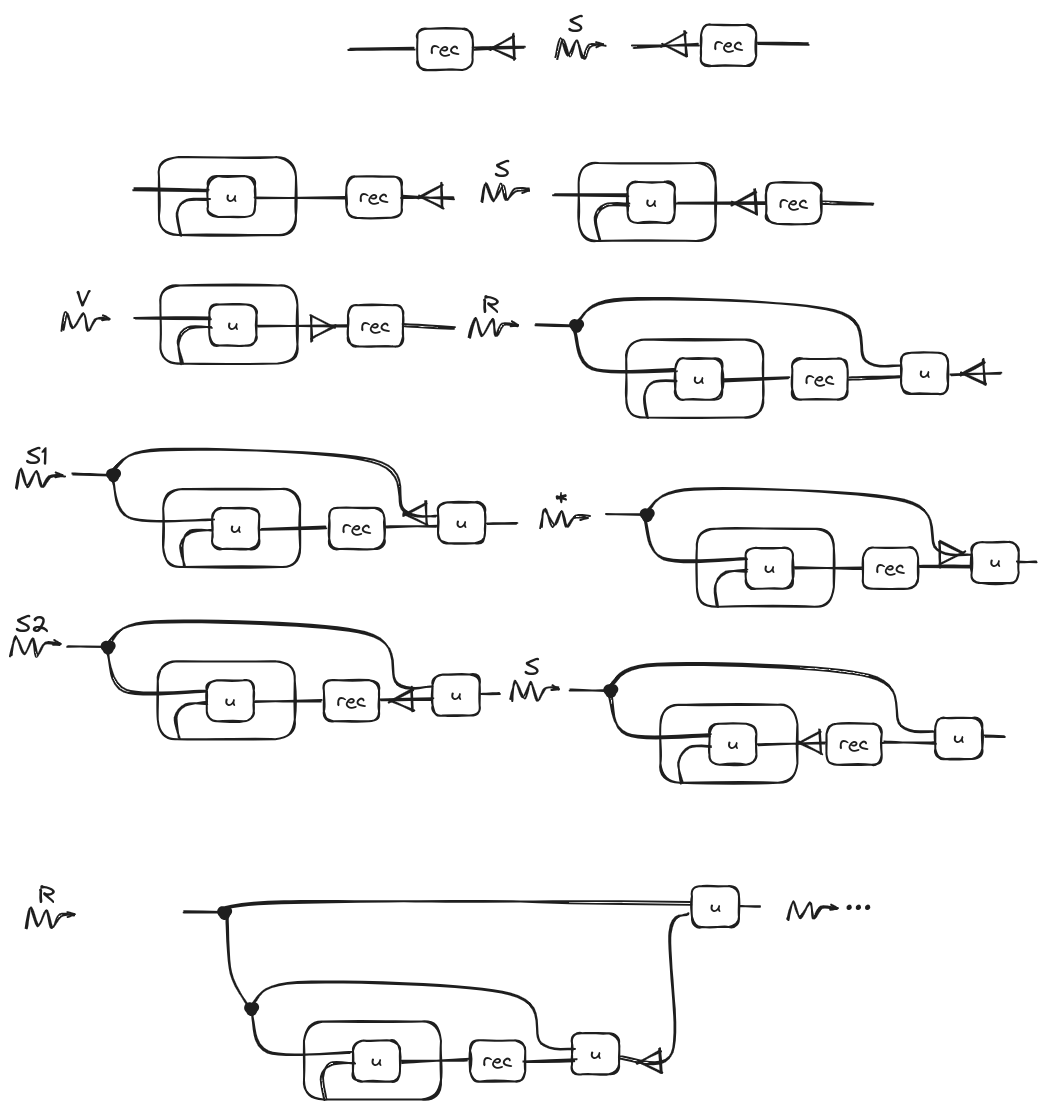
Of course, if we want to have a finite diagram, we should provide an that includes a base case, ensuring that the expansion stops at some point.
Another fun exercise for the non-lazy reader: How could we add an if-then-else operation to our language?
Hint: we should first introduce have a new type (with it respective two constants) and then an operation with the following type: . Now what remains is to provide the definition of the operation and the operational rules for the string diagram interpretation.
Conclusion
Throughout the blog, we not only reviewed the notation of string diagrams for monoidal categories, but also explored how to represent the entire categorical structure behind simply typed lambda calculus. With this in hand, we developed a set of intuitive rules for modeling computation, in the style of operational semantics, which allowed us to add the desired features to our basic language. In particular, we provided examples of operations and recursion, but it doesn’t stop there, we invite the readers to have fun with what they’ve learned and see what features of their favorite programming language they can represent with this model. On the other hand, this blog can be considered another great example of the power of string diagrams. In particular, we, the authors, see it as a significant motivation for our research topic during the research week previous to the ACT conference in Oxford, which will focus on algorithmic methods behind certain rewriting problems of the kind of string diagrams presented in this blog.
Re: An Operational Semantics of Simply-Typed Lambda Calculus With String Diagrams
Seems that there should be a link here but it’s missing.