How the Simplex is a Vector Space
Posted by Tom Leinster
.")
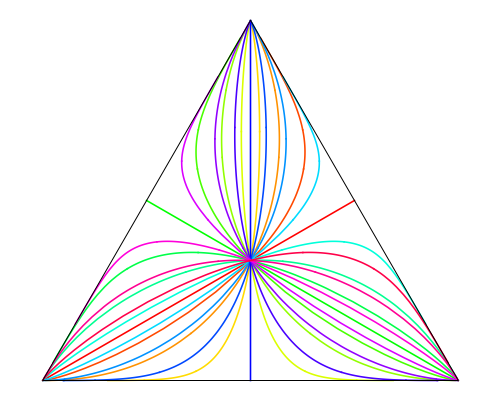
It’s an underappreciated fact that the interior of every simplex is a real vector space in a natural way. For instance, here’s the 2-simplex with twelve of its 1-dimensional linear subspaces drawn in:

(That’s just a sketch. See below for an accurate diagram by Greg Egan.)
In this post, I’ll explain what this vector space structure is and why everyone who’s ever taken a course on thermodynamics knows about it, at least partially, even if they don’t know they do.
Let’s begin with the most ordinary vector space of all, . (By “vector space” I’ll always mean vector space over .) There’s a bijection
between the real line and the positive half-line, given by exponential in one direction and log in the other. Doing this bijection in each coordinate gives a bijection
So, if we transport the vector space structure of along this bijection, we’ll produce a vector space structure on . This new vector space is isomorphic to , by definition.
Explicitly, the “addition” of the vector space is coordinatewise multiplication, the “zero” vector is , and “subtraction” is coordinatewise division. The scalar “multiplication” is given by powers: multiplying a vector by a scalar gives .
Now, the ordinary vector space has a linear subspace spanned by . That is,
Since the vector spaces and are isomorphic, there’s a corresponding subspace of , and it’s given by
But whenever we have a linear subspace of a vector space, we can form the quotient. Let’s do this with the subspace of . What does the quotient look like?
Well, two vectors represent the same element of if and only if their “difference” — in the vector space sense — belongs to . Since “difference” or “subtraction” in the vector space is coordinatewise division, this just means that
So, the elements of are the equivalence classes of -tuples of positive reals, with two tuples considered equivalent if they’re the same up to rescaling.
Now here’s the crucial part: it’s natural to normalize everything to sum to . In other words, in each equivalence class, we single out the unique tuple such that . This gives a bijection
where is the interior of the -simplex:
You can think of as the set of probability distributions on an -element set that satisfy Cromwell’s rule: zero probabilities are forbidden. (Or as Cromwell put it, “I beseech you, in the bowels of Christ, think it possible that you may be mistaken.”)
Transporting the vector space structure of along this bijection gives a vector space structure to . And that’s the vector space structure on the simplex.
So what are these vector space operations on the simplex, in concrete terms? They’re given by the same operations in , followed by normalization. So, the “sum” of two probability distributions and is
the “zero” vector is the uniform distribution
and “multiplying” a probability distribution by a scalar gives
For instance, let’s think about the scalar “multiples” of
“Multiplying” by gives
which I’ll call , to avoid the confusion that would be created by calling it .
When , is just the uniform distribution — which of course it has to be, since multiplying any vector by the scalar has to give the zero vector.
For equally obvious reasons, has to be just .
When is large and positive, the powers of dominate over the powers of the smaller numbers and , so as .
For similar reasons, as . This behaviour as is the reason why, in the picture above, you see the curves curling in at the ends towards the triangle’s corners.
Some physicists refer to the distributions as the “escort distributions” of . And in fact, the scalar multiplication of the vector space structure on the simplex is a key part of the solution of a very basic problem in thermodynamics — so basic that even I know it.
The problem goes like this. First I’ll state it using the notation above, then afterwards I’ll translate it back into terms that physicists usually use.
Fix . Among all probability distributions satisfying the constraint
which one minimizes the quantity
It makes no difference to this question if are normalized so that (since multiplying each of by a constant doesn’t change the constraint). So, let’s assume this has been done.
Then the answer to the question turns out to be: the minimizing distribution is a scalar multiple of in the vector space structure on the simplex. In other words, it’s an escort distribution of . Or in other words still, it’s an element of the linear subspace of spanned by . Which one? The unique one such that the constraint is satisfied.
Proving that this is the answer is a simple exercise in calculus, e.g. using Lagrange multipliers.
For instance, take and . Among all distributions that satisfy the constraint
the one that minimizes is some escort distribution of . Maybe one of the curves shown in the picture above is the 1-dimensional subspace spanned by , and in that case, the that minimizes is somewhere on that curve.
The location of on that curve depends on the value of , which here I chose to be . If I changed it to or then would be nearly at one end or the other of the curve, since converges to as and to as .
Aside I’m glossing over the question of existence and uniqueness of solutions to the optimization question. Since is a kind of average of — a weighted, geometric mean — there’s no solution at all unless . As long as that inequality is satisfied, there’s a minimizing , although it’s not always unique: e.g. consider what happens when all the s are equal.
Physicists prefer to do all this in logarithmic form. So, rather than start with , they start with ; think of this as substituting and . So, the constraint
becomes
or equivalently
We’re trying to minimize subject to that constraint, and again the physicists prefer the logarithmic form (with a change of sign): maximize
That quantity is the Shannon entropy of the distribution : so we’re looking for the maximum entropy solution to the constraint. This is called the Gibbs state, and as we saw, it’s a scalar multiple of in the vector space structure on the simplex. Equivalently, it’s
for whichever value of satisfies the constraint. The denominator here is the famous partition function.
So, that basic thermodynamic problem is (implicitly) solved by scalar multiplication in the vector space structure on the simplex. A question: does addition in the vector space structure on the simplex also have a role to play in physics?
Re: How the Simplex is a Vector Space
One could wonder whether the vector space construction in simplices can relate to Eduoard Lucas’ observation that 1 and 24 are the only two numbers that satisfy the pyramidal square stacking of his Diophantine equation of the so called ‘cannonball problem’. The norm zero Weyl vector from this relation is used in a construction of the Leech lattice as mentioned in Conway and Sloane’s ‘Lorentzian Forms for the Leech Lattice’.This is stated ,”We assert that the Leech lattice can be regarded as the set of all vectors of L orthogonal to w = (0,1,2,…23,24:70)”. The pyramidal square number 70^2 = 4900 can also be expressed as 140 tetrahedral units having 35 elements each or 35 squared pyramidal units having 140 elements each.