The Magnitude of Information
Posted by Tom Leinster
.")
Guest post by Heiko Gimperlein, Magnus Goffeng and Nikoletta Louca
The magnitude of a metric space does not require further introduction on this blog. Two of the hosts, Tom Leinster and Simon Willerton, conjectured that the magnitude function of a convex body with Euclidean distance captures classical geometric information about :
where is proportional to the -th intrinsic volume of and is the volume of the unit ball in .
Even more basic geometric questions have remained unknown, including:
- What geometric content is encoded in ?
- What can be said about the magnitude function of the unit disk ?
We discuss in this post how these questions led us to possible relations to information geometry. We would love to hear from you:
- Is magnitude an interesting invariant for information geometry?
- Is there a category theoretic motivation, like Lawvere’s view of a metric space as an enriched category?
- Does the magnitude relate to notions studied in information geometry?
- Do you have interesting questions about this invariant?
Recent years have seen much progress to understand the geometric content of the magnitude function for domains in odd-dimensional Euclidean space. In this setting Meckes and Barceló–Carbery showed how to compute magnitude using differential equations. Nevertheless, as Carbery often emphasized, hardly anything was known even for such simple geometries as the unit disk in .
Our new works Semiclassical analysis of a nonlocal boundary value problem related to magnitude and The magnitude and spectral geometry show, in particular, that as ,
and that is not a polynomial.
The approach does not use differential equations, but methods for integral equations. Recall that the magnitude of a positive definite compact metric space is defined as
where is the unique distribution supported in that solves the integral equation
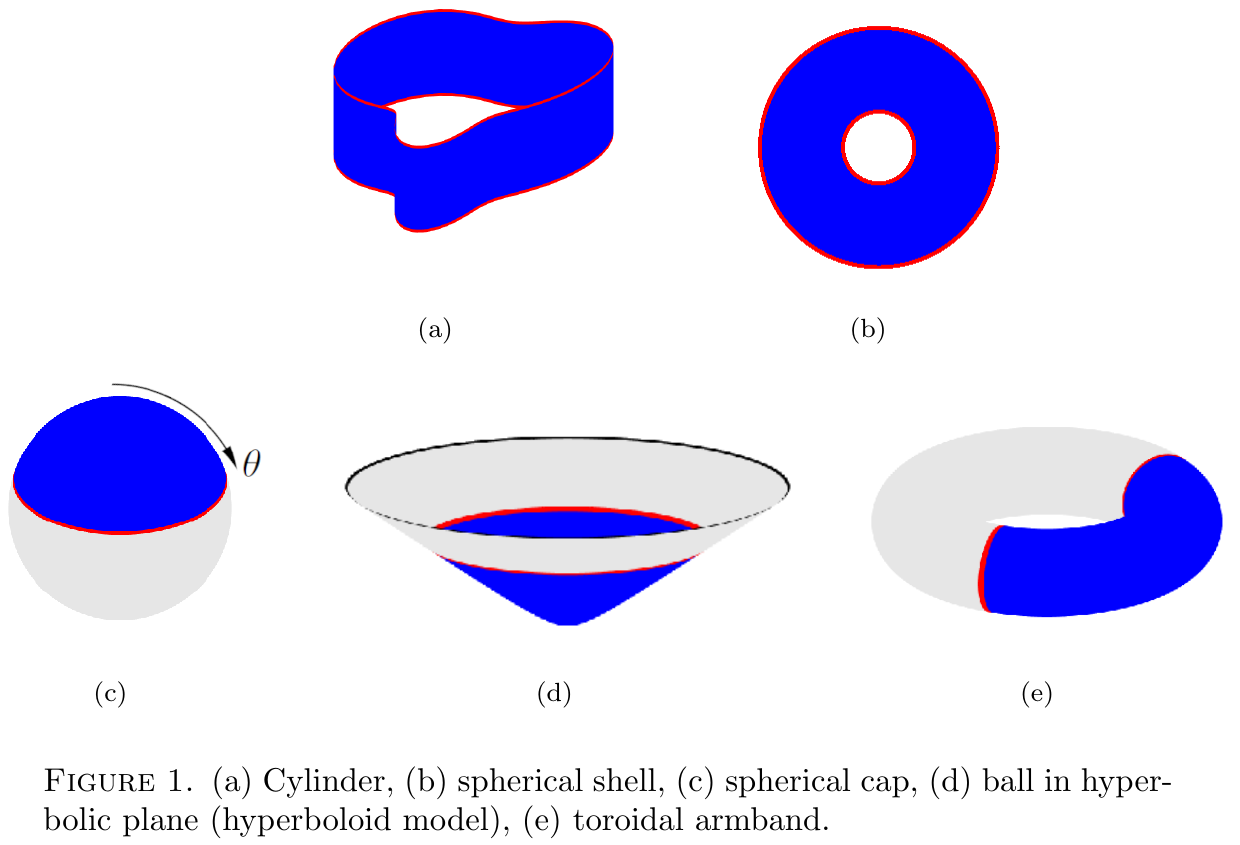
We analyze this integral equation in geometric settings, for domains in , in spheres, tori or, generally, a manifold with boundary with a distance function of any dimension, as illustrated in the figures above. Our results shed light on the geometric content of their magnitude. In fact, our results apply beyond classical geometry and metric spaces — not even a distance function is needed!
Our techniques suggest a life of magnitude beyond metric spaces in information geometry. There one considers a statistical manifold, i.e. a smooth manifold with a divergence , not with a distance function: See John Baez’s posts on information geometry. A first example of a divergence is the square of the subspace distance on a submanifold in Euclidean space. A second example is the square of the geodesic distance function on a Riemannian manifold , provided that it is smooth. (Note that on a circle the distance function and its square are non-smooth when and are conjugate points.) In general, a divergence is a smooth, non-negative function such that is a Riemannian metric near modulo lower order terms, in the sense that
for a Riemannian metric on .
Divergences related to relative entropy have long been used in statistics to study families of probability measures. The relative entropy of two probability measures and on a space is defined as
The notion of relative entropy and its cousins are discussed in the blog posts of Baez mentioned above and also in Leinster’s book Entropy and Diversity: The Axiomatic Approach. While the space of probability measures is too big, one can restrict to interesting submanifolds (with boundary).
Here is the definition of the magnitude function of a statistical manifold with boundary , when is sufficiently large:
where is the unique distribution supported in that solves the integral equation
When is the square of a distance function on , we recover the magnitude of the metric space .
We emphasize two key points to take home:
The integral equation approach is equivalent to defining the magnitude of statistical manifolds using Meckes’s classical approach in Magnitude, diversity, capacities, and dimensions of metric spaces, relying on reproducing kernel Hilbert spaces.
Since is smooth, shares the properties stated in The magnitude and spectral geometry for the magnitude function summarized next.
Theorem
a. The magnitude is well-defined for sufficiently large; there the integral equation admits a unique distributional solution.
b. extends meromorphically to the complex plane.
c. The asymptotic behavior of is determined by the Taylor coefficients of and .
Further details and explicit computations of the first few terms (X) can be found in The magnitude and spectral geometry: For a Riemannian manifold is proportional to the volume of , while is proportional to the surface area of . involves the integral of the scalar curvature of and the integral of the mean curvature of . All these computations are relative to and the Riemannian metric that defines. For Euclidean domains , is proportional to the Willmore energy of (proven with older technology in another paper: The Willmore energy and the magnitude of Euclidean domains). We note that
in all known computations of asymptotics for Euclidean domains , is proportional to for .
Here denotes the mean curvature of . You can compute lower-order terms by an iterative scheme, for as long as you have the time. In fact, we have written a python code which computes for any , which is available at arXiv:2201.11363.
We would love to hear from you should you have any thoughts on the following questions:
Is magnitude an interesting invariant for information geometry?
Is there a category theoretic motivation, like Lawvere’s view of a metric space as an enriched category?
Does the magnitude relate to notions studied in information geometry?
Do you have interesting questions about this invariant?
Re: The Magnitude of Information
There’s loads of good stuff here, but let me highlight one particular point: finally, we know something about the magnitude of a Euclidean disc!
Some context:
We’ve known from the start that the magnitude of a 1-dimensional ball — that is, a line segment — is a polynomial of degree 1 in its radius (or length).
Juan Antonio Barceló and Tony Carbery showed that the magnitude of a 3-dimensional ball is a polynomial of degree 3 in its radius.
They also showed that in odd dimensions , the magnitude of a -dimensional ball is a rational function in the radius, but not a polynomial.
And we’ve known for a long time that for every , the magnitude of the -dimensional ball of radius grows like as . This explains the degrees of the polynomials just mentioned.
What we didn’t know much about until Heiko, Magnus and Nikoletta’s work is the magnitude of even-dimensional balls. As they say in the post above, the 2-dimensional ball of radius has magnitude
as , and it’s not a polynomial in !
So we have a funny situation:
the magnitude of a 1-dimensional ball is a polynomial in its radius;
the magnitude of a 3-dimensional ball is a polynomial in its radius;
but the magnitude of a 2-dimensional ball is not.
I have a very rough idea of why that’s the case, but really not what you could call a conceptual explanation. Finding a conceptual explanation seems like a real challenge.