Linguistics Using Category Theory
Posted by John Baez
.")
guest post by Sarah Griffith and Jade Master
Most recently, the Applied Category Theory Seminar took a step into linguistics by discussing the 2010 paper Mathematical Foundations for a Compositional Distributional Model of Meaning, by Bob Coecke, Mehrnoosh Sadrzadeh, and Stephen Clark.
Here is a summary and discussion of that paper.
In recent years, well known advances in AI, such as the development of AlphaGo and the ongoing development of self driving cars, have sparked interest in the general idea of machines examining and trying to understand complex data. In particular, a variety of accounts of successes in natural language processing (NLP) have reached wide audiences (see, for example, The Great AI Awakening).
One key tool for NLP practitioners is the concept of distributional semantics. There is a saying due to Firth that is so often repeated in NLP papers and presentations that even mentioning its ubiquity has become a cliche:
“You shall know a word by the company it keeps.”
The idea is that if we want to know if two words have similar meanings, we should examine the words they are used in conjunction with, and in some way measure how much overlap there is. While direct ancestry of this concept can be traced at least back to Wittgenstein, and the idea of characterizing an object by its relationship with other objects is one category theorists are already fond of, distributional semantics is distinguished by its essentially statistical methods. The variations are endless and complex, but in the cases relevant to our discussion, one starts with a corpus, a suitable way of determining what the context of a word is (simply being nearby, having a grammatical relationship, being in the same corpus at all, etc) and ends up with a vector space in which the words in the corpus each specify a point. The distance between vectors (for an appropriate definition of distance) then correspond to relationships in meaning, often in surprising ways. The creators of the GloVe algorithm give the example of a vector space in which .
There is also a “top down,” relatively syntax oriented analysis of meaning called categorial grammar. Categorial grammar has no accepted formal definition, but the underlying philosophy, called the principle of compositionality, is this: a meaningful sentence is composed of parts, each of which itself has a meaning. To determine the meaning of the sentence as a whole, we may combine the meanings of the constituent parts according to rules which are specified by the syntax of the sentence. Mathematically, this amounts to constructing some algebraic structure which represents grammatical rules. When this algebraic structure is a category, we call it a grammar category.
The Paper
Preliminaries
Pregroups are the algebraic structure that this paper uses to model grammar. A pregroup P is a type of partially ordered monoid. Writing to specify that in the order relation, we require the following additional property: for each , there exists a left adjoint and a right adjoint , such that and . Since pregroups are partial orders, we can regard them as categories. The monoid multiplication and adjoints then upgrade the category of a pregroup to compact closed category. The equations referenced above are exactly the snake equations.
We can define a pregroup generated by a set by freely adding adjoints, units and counits to the free monoid on . Our grammar categories will be constructed as follows: take certain symbols, such as for noun and for sentence, to be primitive. We call these “word classes.” Generate a pregroup from them. The morphisms in the resulting category represent “grammatical reductions” of strings of word classes, with a particular string being deemed “grammatical” if it reduces to the word class . For example, construct the pregroup generated by and . A transitive verb can be thought of as accepting two nouns, one on the left and one on the right, and returning a sentence. Using the powerful graphical language for compact closed categories, we can represent this as

Using the adjunctions, we can turn the two inputs into outputs to get

Therefore the type of a verb is . Multiplying this on the left and right by allows us to apply the counits of to reduce to the type , as witnessed by
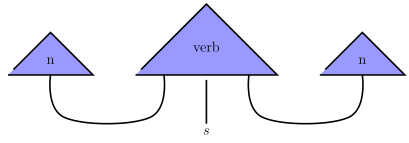
Let be the symmetric monoidal category of finite dimensional vector spaces and linear transformations with the standard tensor product. Since any vector space we use in our applications will always come equipped with a basis, these vector spaces are all endowed with an inner product. Note that has a compact closed structure. The counit is the diagonal
and the unit is a linear extension of the inner product
The Model of Meaning
Let be a pregroup. The ingenious idea that the authors of this paper had was to combine categorial grammar with distributional semantics. We can rephrase their construction in more general terms by using a compact closed functor
Unpacking this a bit, we assign each word class a vector space whose basis is a chosen finite set of context words. To each type reduction in , we assign a linear transformation. Because is strictly monoidal, a string of word classes maps to a tensor product of vector spaces .
To compute the meaning of a string of words you must:
Assign to each word a string of symbols according to the grammatical types of the word and your choice of pregroup formalism. This is nontrivial. For example, many nouns can also be used as adjectives.
Compute the correlations between each word in your string and the context words of the chosen vector space (see the example below) to get a vector ,
choose a type reduction in your grammar category (there may not always be a unique type reduction) and,
apply to your vector .
You now have a vector in whatever space you reduced to. This is the “meaning” of the string of words, according the your model.
This sweeps some things under the rug, because A. Preller proved that strict monoidal functors from a pregroup to actually force the relevant spaces to have dimension at most one. So for each word type, the best we can do is one context word. This is bad news, but the good news is that this problem disappears when more complicated grammar categories are used. In Lambek vs. Lambek monoidal bi-closed categories are used, which allow for this functorial description. So even though we are not really dealing with a functor when the domain is a pregroup, it is a functor in spirit and thinking of it this way will allow for generalization into more complicated models.
An Example
As before, we use the pregroup . The nouns that we are interested in are
These nouns form the basis vectors of our noun space. In the order they are listed, they can be represented as
The “sentence space” is taken to be a one dimensional space in which corresponds to false and the basis vector corresponds to true. As before, transitive verbs have type , so using our functor , verbs will live in the vector space . In particular, the verb “like” can be expressed uniquely as a linear combination of its basis elements. With knowledge of who likes who, we can encode this information into a matrix where the -th entry corresponds to the coefficient in front of . Specifically, we have
The -th entry is if person likes person and otherwise. To compute the meaning of the sentence “Maria likes Cynthia”, you compute the matrix product
This means that the sentence “Maria likes Cynthia” is true.
Food for Thought
As we said above, this model does not always give a unique meaning to a string of words, because at various points there are choices that need to be made. For example, the phrase “squad helps dog bite victim” has a different meaning depending on whether you take “bite” to be a verb or a noun. Also, if you reduce “dog bite victim” before applying it to the verb, you will get a different meaning than if you reduce “squad helps dog” and apply it to the verb “bite”. On the one hand, this a good thing because those sentences should have different meanings. On the other hand, the presence of choices makes it harder use this model in a practical algorithm.
Some questions arose which we did not have a clear way to address. Tensor products of spaces of high dimension quickly achieve staggering dimensionality — can this be addressed? How would one actually fit empirical data into this model? The “likes” example, which required us to know exactly who likes who, illustrates the potentially inaccessible information that seems to be necessary to assign vectors to words in a way compatible with the formalism. Admittedly, this is a necessary consequence of the fact the evaluation is of the truth or falsity of the statement, but the issue also arises in general cases. Can this be resolved? In the paper, the authors are concerned with determining the meaning of grammatical sentences (although we can just as easily use non-grammatical strings of words), so that the computed meaning is always a vector in the sentence space . What are the useful choices of structure for the sentence space?
This paper was not without precedent — suggestions and models related its concepts of this paper had been floating around beforehand, and could be helpful in understanding the development of the central ideas. For example, Aerts and Gabora proposed elaborating on vector space models of meaning, incidentally using tensors as part of an elaborate quantum mechanical framework. Notably, they claimed their formalism solved the “pet fish” problem - English speakers rate goldfish as very poor representatives of fish as a whole, and of pets as a whole, but consider goldfish to be excellent representatives of “pet fish.” Existing descriptions of meaning in compositional terms struggled with this. In The Harmonic Mind, first published in 2005, Smolensky and Legendre argued for the use of tensor products in marrying linear algebra and formal grammar models of meaning. Mathematical Foundations for a Compositional Distributional Model of Meaning represents a crystallization of all this into a novel and exciting construction, which continues to be widely cited and discussed.
We would like to thank Martha Lewis, Brendan Fong, Nina Otter, and the other participants in the seminar.


Re: Linguistics Using Category Theory
Shouldn’t that be “Smolensky and Legendre”? Stephen Pulman is involved in the field but didn’t author that book.
Also I would like to point out that in this perspective meaning is conflated with truth-conditional semantics which might be regarded as a sanity check on grammars that contain quantifiers and maybe modalities and at best allow inferences on the truth of sets of sentences to conclude things like “Socrates is mortal”. I am unaware of any applied NLP system that uses truth inference. In a system for for language translation this notion of “meaning” becomes just figuring out for a string of words their most likely word classes, senses, and grammatical relations between them.
Often what can be considered the meaning of a sentence involves filling in implicit information. For example the meaning of the sentence:
should contain
Different languages have different strategies for how to leave information implicit.